Sign up for the ITPro Today newsletter
Stay on top of the IT universe with commentary, news analysis, how-to's, and tips delivered to your inbox daily.
Azure Cosmos DB introduces career- and technical-related questions for traditional DBAs; how it handles scalability, by scaling out rather than up, distinguishes it from SQL Server.
June 15, 2018

Azure Cosmos DB is Microsoft’s NoSQL database as a service (DaaS), designed to take advantage of elasticity and flexibility and to satisfy the needs of IoT and global-facing, cloud-based applications. It offers access methods, consistency models, cost structures and ways of looking at data that are different from a relational database management system (RDBMS) like SQL Server.
But Cosmos DB introduces a number of questions for database professionals. Most of the seasoned DBAs I know are struggling to wrap their heads around exactly what Cosmos DB is and wondering where it should or should not be used. And beyond the need to understand and evaluate the technical aspects of Cosmos DB, there is a broader set of questions around what the technology means for traditional DBAs’ careers. Should RDMBS specialists become database generalists? Doing so would allow them to get more involved in NoSQL and Cosmos DB but it comes at the cost of less depth of knowledge in the RDBMS space.
So to help RDBMS specialists with this decision-making process, I’m writing a series of articles that explain Azure Cosmos DB from a SQL Server DBA’s perspective. I plan to shed some light on what exactly it is and what it means to someone who has spent most of their career in the relational database space. The idea is to present the basic building blocks of Cosmos DB so that you can decide whether or not to invest more of yourself in this new tech.
Before we dig in, let’s get something out of the way. Cosmos DB is not a replacement for SQL Server. You would very, very rarely, if ever, migrate your data from an existing SQL Server database to Cosmos DB. The only cases I can imagine where this would make any sort of sense would be if there had been a complete misuse of SQL Server in the first place, like saving vast amounts of static XML or JSON (JavaScript Object Notation) into a SQL Server database, or if you’d been attempting to use SQL Server as the back end for a high-transaction, globally distributed application. But even in these cases, I wouldn’t recommend a migration but rather a re-architecture and rewrite.
Now let’s talk about one important difference between SQL Server and Azure Cosmos DB: scalability methods. SQL Server primarily achieves scale by scaling up, while Cosmos DB does so by scaling out.
The idea of scaling out a database can make DBAs nervous because it involves multiple copies of the “truth.” Those multiple copies eventually get in sync with one another, but for traditional DBAs who have relied upon a single version of the “truth” (and a model wherein all changes reside in a single region on a single server) to ensure data protection, scaling out represents a lot of uncertainty and conflict.
The two platforms differ around scalability because of their basic design: SQL Server was built with data consistency and integrity as the No. 1 mission, while Cosmos DB was designed for geographic distribution and speed, moving the data closer to the user and with features tightly coupled with the needs of IoT systems. Like all NoSQL database platforms, eventual consistency is a primary principle for Cosmos DB.
In SQL Server, to ensure data consistency and integrity, transactions are handled sequentially and almost always committed to a single server. If you need more power or throughput, you add more hardware (CPU, memory, disk speed, disk size, network bandwidth). The nice thing about this approach is that it is simple. You just throw money at the problem and (hopefully) things go faster.
While there are ways to scale SQL Server out, they only help with performance when it comes to read-only activity. Database alterations (inserts, updates and deletes) do not experience performance boosts from SQL Server's scale-out strategies -- other than the reduction of competing read-only access. For use cases where scaling out for read-only activity makes sense, replication and Availability Groups can be used. Both methods involve a single read/write primary node and one or many read-only nodes. This works well if, for instance, you need to make globally available your reporting structure (which is read-only by nature). But, again, if you’re trying to make inserting, updating or deleting records faster, having a single node as the "hub for changing data" can only get you so far.
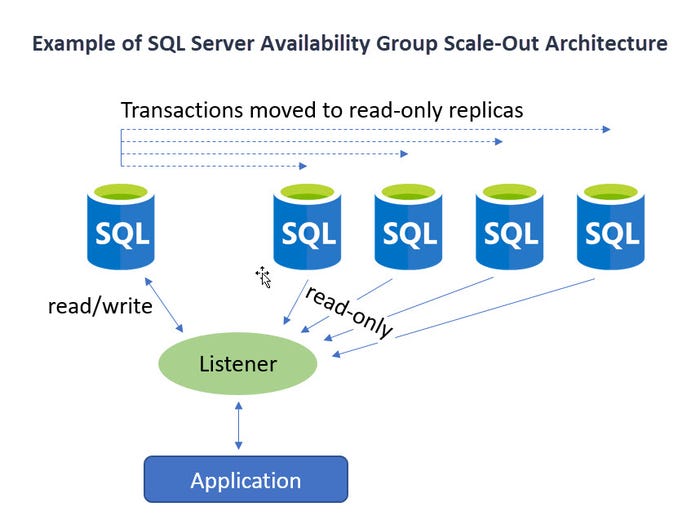
AG_Scaleout_3
With Azure Cosmos DB, on the other hand, there isn’t exactly a way to scale up. Cosmos DB is designed to scale out by utilizing many regional machines and then mirroring this structure geographically to bring content closer to users worldwide. It’s kind of like RAID 10 was to disk (mirroring and striping), but by mirroring across multiple geographies and then striping across nodes. The database container is partitioned using hashing keys that you provide. Each range of hashed values is stored on a particular machine (a node). Every node can accept reads and writes and in turn naturally replicates to the other nodes. This means there is no single hub for all write activity. Cosmos DB is superfast, but the database itself doesn’t take the time to reject a change because it violates a policy. And, if the database runs into trouble, it can’t easily be rolled back to a point in time before things went awry.
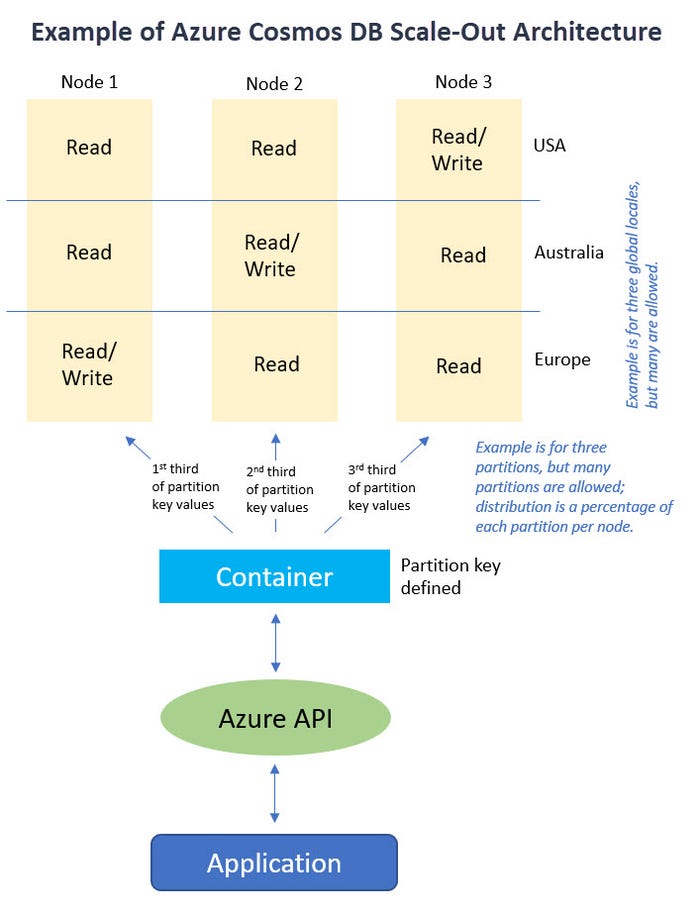
Cosmos_DB_Scaleout_3
Next up, in Part 2 of this series, I’ll dig into the concepts of containers and collections in Cosmos DB.
Looking for an awesome, no-nonsense technical conference for IT pros, developers and DevOps? IT/Dev Connections kicks off in Dallas in 2018! And make sure to check out the data platform track, for which Mindy Curnutt serves as the chairwoman.

ITDC_2
You May Also Like






.jpg?width=700&auto=webp&quality=80&disable=upscale)
